
Was ist OCR?
Die Digitalisierung von Papierunterlagen kann für Unternehmen enorme Effizienzsteigerungen bedeuten. Einmal konvertiert, lassen sich die Daten softwaregestützt durchsuchen, sortieren und analysieren, um wertvolle Erkenntnisse zu gewinnen. Möglich wird dies durch “Optical Character Recognition”, kurz OCR.
Obwohl die Bezeichnung weithin bekannt ist, wissen nur wenige, welche Prozesse wirklich dahinterstecken. Bevor wir uns mit den technischen Details befassen, sollten wir zwischen den verschiedenen Kategorien maschineller Texterkennung unterscheiden, die unter den Sammelbegriff OCR fallen:
- Optical character recognition (OCR im engeren Sinn): Erkennung von einzelnen gedruckten Zeichen
- Optical word recognition (OWR): Erkennung von ganzen gedruckten Wörtern
- Intelligent character recognition (ICR): Erkennung von einzelnen gedruckten oder handgeschriebenen Zeichen, nutzt Machine Learning
- Intelligent word recognition (IWR): Erkennung von ganzen gedruckten oder handgeschriebenen Wörtern, nutzt Machine Learning
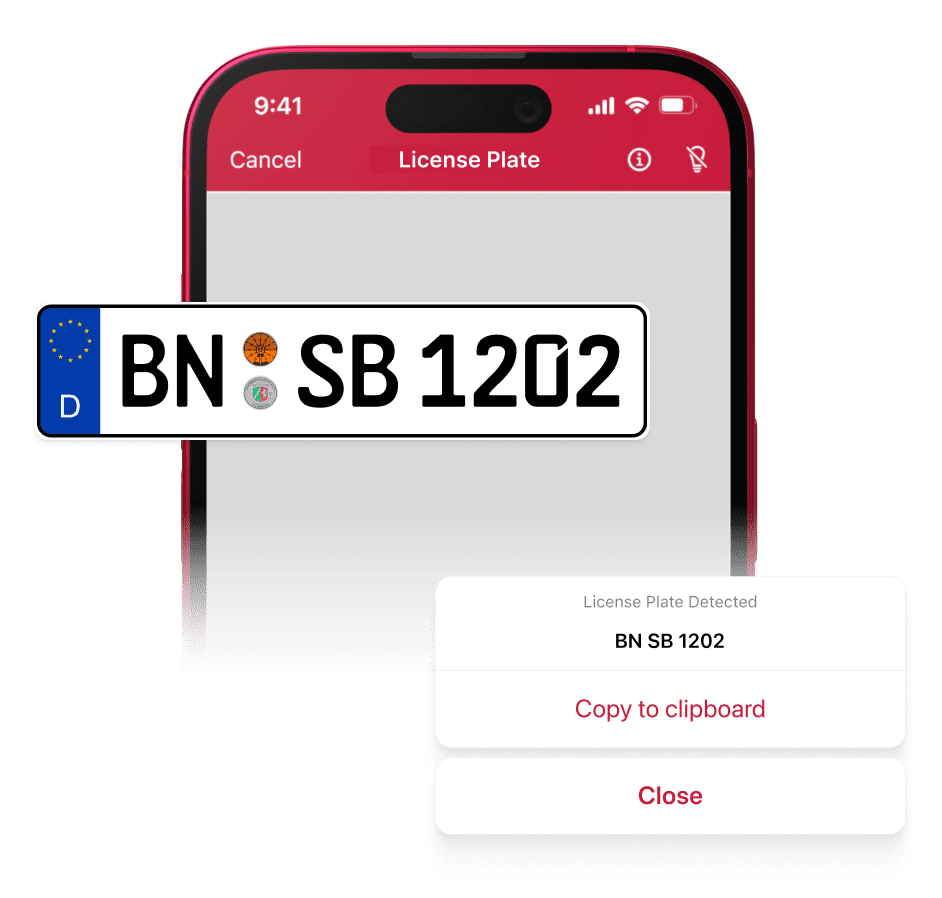
Es macht zudem einen Unterschied, ob Sie ausschließlich Informationen aus Dokumenten oder Text in allen möglichen Umgebungen erfassen möchten, beispielsweise auf Autokennzeichen oder Schildern. Letzteres ist wesentlich schwieriger, da Variablen wie Winkel, Kontrast und aufwendige Schriftarten eine Rolle spielen. Wählen Sie daher Ihre Software-Lösung mit Bedacht und unter Berücksichtigung der genannten Faktoren aus.

Aufbereitung für OCR
Für möglichst gute Ergebnisse sollten die zu verarbeitenden Bilddateien vorbereitet werden, bevor die eigentliche Texterkennung durch die OCR-Software beginnt.
Auch bei Flachbett-Scannern ist das Ergebnis etwa häufig leicht verzerrt. Wird dies korrigiert, fällt es der OCR-Software leichter, die Textzeilen korrekt zu erfassen und somit etwa Wörter besser voneinander zu trennen.
Als nächstes folgt die Binarisierung. Dabei wird ein Dokument in Farbe oder Graustufen auf Schwarz-Weiß reduziert, sodass sich der Text eindeutig vom Hintergrund abhebt. Je nach Qualität des Inputs kommt es vor, dass der Hintergrund nicht vollständig entfernt werden kann. Das führt zu einem körnigen Bild, was die Texterkennung erschwert. Vor der Binarisierung können daher Bildfilter zum Einsatz kommen, die dem entgegenwirken.
Textausgabe und Nachbearbeitung
Nachdem die OCR-Software das gesamte Dokument erfasst hat, gibt sie den enthaltenen Text in digitaler Form wieder aus. Hierfür stehen unterschiedliche Möglichkeiten zur Auswahl. Am einfachsten ist das Erstellen einer reinen Textdatei, in der der Inhalt als ein einziger Textblock ohne Zeilenumbrüche und Formatierung gespeichert wird. Für sehr kurze Texte mag diese Vorgehensweise ausreichen, für größere Dokumente oder komplexe Formulare ist sie aber ungeeignet.
Manche Tools geben eine Word-Datei aus und versuchen dabei die Formatierung des ursprünglichen Dokuments nachzuahmen. Das Ergebnis ist aber selten optimal, besonders wenn die Datei später bearbeitet werden soll.
Eine weitere Möglichkeit ist, den erfassten Text als unsichtbare Ebene über eine PDF-Version der ursprünglichen Bilddatei zu legen. Damit bleibt das Aussehen perfekt erhalten, der Text lässt sich nun aber auch durchsuchen und markieren.
OCR-Texterkennung mit Machine Learning verbessern
Höchste Genauigkeit ist gerade dann wichtig, wenn mittels OCR-Technologie extrahierte Daten automatisch weiterverarbeitet werden sollen, um die manuelle Dateneingabe zu ersetzen. In diesem Fall kann maschinelles Lernen dabei helfen, genauere Ergebnisse zu erzielen.
Erschwert wird die Datenextraktion von der Vielfältigkeit der relevanten Dokumente. Machine-Learning-Algorithmen können hier Abhilfe schaffen: Die Modelle werden dazu für die Erkennung vieler verschiedener Dokumententypen trainiert. So können sie schnell die benötigten Daten erkennen und als Schlüssel-Wert-Paare extrahieren – das ideale Format für die Weiterverarbeitung.
Möchten Sie Text abseits von Dokumenten erfassen, ist die Unterstützung von Machine Learning für die OCR unerlässlich. Nehmen wir an, Sie wollen die Kennzeichen von Fahrzeugen auf Ihrem Unternehmensgelände mithilfe eines Kennzeichen Scanners erfassen: OCR-Texterkennung allein reicht hier nicht aus. Stattdessen benötigen Sie ein auf diese Aufgabe trainiertes Deep-Learning-Modell, welches die Kennzeichen zunächst erkennt und erfasst, die Bilddateien für die Weiterverarbeitung anpasst, die einzelnen Zeichen ausliest und schließlich in einem maschinenlesbaren Format speichert.
Einsatz von OCR zur Optimierung von Arbeitsabläufen
Viele Unternehmen setzen inzwischen zunehmend auf digitales Dokumentenmanagement. Hierfür kann beispielsweise jedes eingehende Papierdokument eingescannt und elektronisch im System abgelegt werden, um den Zugriff für alle zu gewährleisten. Direkt im Anschluss wird das Original archiviert.
Wird auf diese Dokumente zusätzlich OCR angewendet, lassen sie sich nach Stichwörtern wie Firmenname, Datum, Adresse usw. durchsuchen und können so noch Jahre später leicht wiedergefunden werden. Ihre Mitarbeitenden verbringen damit deutlich weniger Zeit damit, nach ihnen zu suchen.
Hat Ihr Unternehmen einen sehr spezifischen Anwendungsfall für die automatische Dokumentenverarbeitung? Sie können sich glücklich schätzen: Je enger Ihre Anforderungen, desto leichter kann man ein Deep-Learning-Modell dafür trainieren. Im ersten Moment mag das einschüchternd klingen, doch die hochwertigen Ergebnisse sind den Aufwand wert.
Das Scanbot Document Scanner SDK verwendet die Tesseract OCR Engine, um Text zu erkennen und in höchstmöglicher Qualität zu digitalisieren. Für optimale Ergebnisse kommen verschiedenste Bildfilter zum Einsatz. Unser Data Capture SDK geht noch einen Schritt weiter und verwendet Machine Learning nicht nur zur automatischen Erkennung verschiedenster Dokumentarten, sondern auch von Text in “freier Wildbahn”. Derzeit arbeiten wir daran, dass unser Deep-Learning-Modell innerhalb von nur drei Arbeitstagen erfolgreich auf einen neuen Dokumententyp trainiert werden kann.
Wenn Sie glauben, dass diese Technologie für Ihren Anwendungsfall interessant sein könnte, kontaktieren Sie gerne unsere Lösungsexpert:innen.. Gerne helfen wir Ihnen dabei, OCR-Texterkennung in Ihre Unternehmensabläufe zu integrieren.