
Bei Scanbot SDK standen mobile Betriebssysteme immer an erster Stelle - Android- und iOS-SDKs waren die ersten SDKs, die wir veröffentlichten. Im Laufe der Zeit, da unsere Kunden die Technologie auf mehr Frameworks und Geräten nutzen wollten, haben wir unser Portfolio erweitert. Schon bald konnten wir SDKs für Cordova, React Native, Flutter, Xamarin und Web-Frameworks anbieten. Unter der Haube verwenden sie alle denselben Kern-Code, der in C++ geschrieben ist. Für jede dieser Plattformen bieten wir Binary Builds an.
Im Jahr 2022 entschieden wir uns dafür, eine weitere Plattform hinzuzufügen. Wir hatten nämlich erfahren, dass Windows-basierte Tablets häufig in Warenlagern verwendet werden.
Als sich mir die Gelegenheit bot, eine Windows-Version des Scanbot SDK von Grund auf zu entwickeln, musste ich sofort zugreifen.
Ich wusste kaum etwas über Windows-Entwicklung, aber das hielt mich nicht davon ab, einige kühne Behauptungen aufzustellen, um das Team zu beeindrucken.
Was bedeutete, dass ich sie auch einhalten musste.
Win32, WPF, MAUI, UWP, WTF?
Als ich in das Microsoft-Ökosystem eintauchte, fiel mir als erstes die Vielfalt der verfügbaren Entwicklungs-Frameworks auf. Es gibt eine Menge seltsamer Akronyme, die für mich anfangs nicht viel Sinn ergaben.
Die erste Frage war also: Welches Framework sollte ich wählen? Welches wäre das stabilste, aber auch das zukunftssicherste?
Die Antwort ist erstaunlich einfach: Momentan ist UWP mit Windows.UI.Xaml angesagt. Die Giganten Win32, WPF und Silverlight gehören eher der Vergangenheit an, während das Durchhaltevermögen der zwei neueren Konkurrenten App SDK und MAUI noch nicht bewiesen ist.
Win32 ist natürlich immer noch die Grundlage für alle oben genannten Frameworks und wird auch dann noch existieren, wenn ich einen langen, grauen Bart habe. Aber um das alles etwas komplizierter zu machen, ist dessen UI-Komponente veraltet.
Da wir es mit dem Microsoft-Ökosystem zu tun haben, ist alles miteinander verwoben. Das Windows.UI.Xaml-Framework ist so etwas wie ein Ableger von WPF und Silverlight. Und Silverlight basiert wiederum auf WPF.
Warum sind all diese Beziehungen wichtig? Hier ein sonderbar spezifisches Beispiel:
Das Scanbot Barcode Scanner SDK bietet ein halbtransparentes Overlay mit einem Loch in der Mitte. Der technische Begriff dafür ist "Viewfinder". Es handelt sich dabei um ein relativ komplexes UI-Element, und ein Loch in ein Overlay zu schneiden, kann je nach Framework trivial sein oder eben nicht.
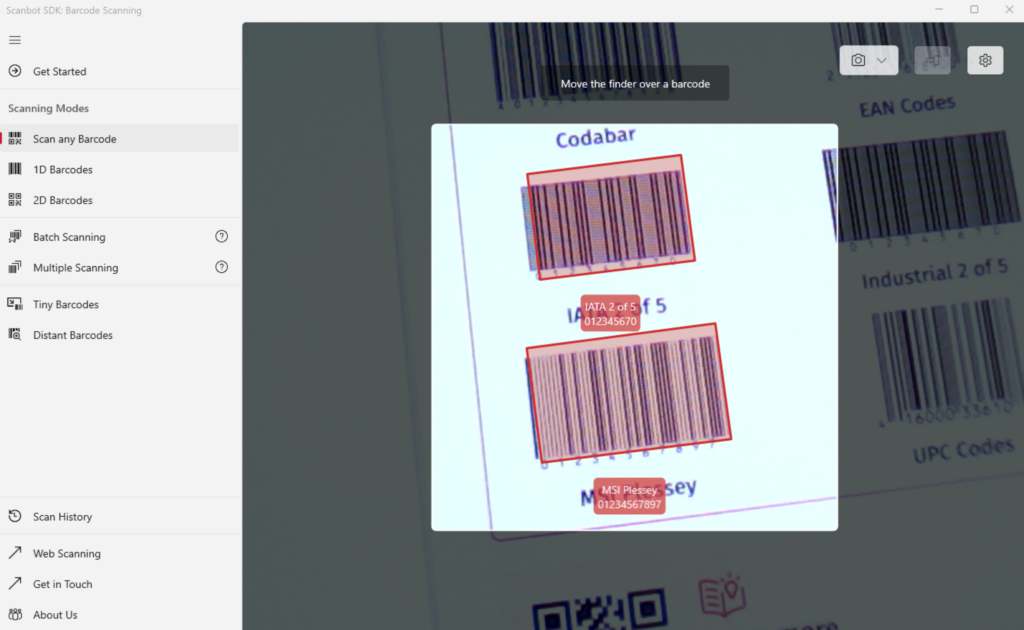
Unter Umständen muss man mittels Mathematik einen Pfad erstellen und ein Polygon ausschneiden, einen geometrischen Punkt nach dem anderen. Wenn man Glück hat, gibt es dafür eine eigene Funktion.
Während meiner Recherche darüber, wie man das Problem angehen könnte, stieß ich in einer Dokumentation auf einen recht einfachen Vorschlag: Den Eckenradius der Löcher im Gitter festlegen und fertig.
Als ich mich jedoch daran versuchte, konnte ich beim besten Willen nicht die benötigten Eigenschaften finden. Ich raufte mir die Haare, stellte dann aber schnell fest, dass die von mir verwendete Anleitung eigentlich für Silverlight geschrieben worden war. Das ist das Problem mit der Dokumentation von Microsoft: Die komplette Dokumentation zu jeder Framework-Version existiert überall gleichzeitig. Die Syntax ist vertraut, die Klassennamen sind gleich, und es wird nicht explizit vermerkt, für welches Framework das, was Sie gerade lesen, eigentlich gedacht ist. Wenn Sie die Namespace-Referenz am Anfang der Seite übersehen (oder nicht kennen), kann es passieren, dass Sie versuchen, ein veraltetes Framework zu implementieren.
Zum Zeitpunkt dieses Artikels war Silverlight bereits seit mehr als drei Jahren nicht mehr erhältlich. Und nun saß ich hier mit meiner Silverlight-Dokumentation.
Dabei war das erst der Anfang. Nun sollte es an die eigentliche Entwicklung des Produkts gehen…
Bridging: P/Invoke, C++/CX und WinRT/C++
Wir mussten eine Möglichkeit finden, den C++-Code unseres Core mit C#, der Hauptsprache von .NET und Windows-Anwendungen, zu verbinden. Auf der Suche nach einer einigermaßen stabilen Lösung haben wir mehrere Möglichkeiten durchgespielt.
Zunächst einmal ermöglichen P/Invoke und COM interop die Verwendung von Code aus unverwalteten .NET-Bibliotheken. Das ist der ursprüngliche Weg, um C++- und C#-Code zu verbinden. Man importiert die DLL direkt über die Attribut-/Anmerkungs-API wie folgt:
// Import user32.dll (containing the function we need) and define
// the method corresponding to the native function.
[DllImport("user32.dll", CharSet = CharSet.Unicode, SetLastError = true)]
private static extern int MessageBox(IntPtr hWnd, string lpText, string lpCaption, uint uType);P/Invoke wird immer noch in einer Vielzahl von Situationen verwendet, da es nur System.Runtime.InteropServices benötigt, was die ganze Lösung vielseitiger macht.
Da das Scanbot SDK jedoch mit .NET-Typen (z. B. SoftwareBitmap) und benutzerdefinierten SDK-Klassen (z. B. BarcodeResult) arbeiten muss, benötigten wir einen moderneren, Debugging-fähigen Ansatz.
Dies führte uns zu den etwas fortschrittlicheren Bridging-Technologien: C++/CX und C++WinRT.
Eine kurze Übersicht: C++ ist eine Programmiersprache, während C++/CX eine Erweiterung von C++ ist, die die Entwicklung von WinRT/UWP-Anwendungen erleichtert. C++/WinRT gehört als Ansatz für Anwendungen einer neuen Generation an. Es handelt sich nicht um eine Erweiterung von C++, sondern einfach um eine API, die auf regulärem C++ basiert.
Ursprünglich hatten wir uns für das Scanbot SDK für den traditionellen Ansatz von C++/CX entschieden, weil es eine längere Erfolgsbilanz hatte, die meisten Anleitungen verfügbar waren, die meisten StackOverflow-Beiträge diese Syntax verwendeten und es sogar Anleitungen gab, wie man OpenCV, einen wesentlichen Bestandteil des Scanbot SDK, bindet und überbrückt.
Dieser Leitfaden hat uns die Arbeit enorm vereinfacht. So gelang es uns, innerhalb weniger Tage einen voll funktionsfähigen Konverter des Kamera-Streams zur OpenCV-Matrix zu erstellen.
Leider war unsere Freude nur von kurzer Dauer, denn wir fanden heraus, dass C++/CX bald eingestellt würde. Da die Syntax unseren C++-Entwicklern ohnehin ein wenig fremd war, beschlossen wir, das Ganze zu streichen und alles in der neuen und verbesserten C++/WinRT-Syntax neu zu schreiben.
Die beiden Hauptunterschiede zwischen C++/CX und C++/WinRT sind die Hat-Operatoren und die Verwendung von mIDL anstelle von ref-Bridging-Klassen.
“The handle declarator (^, pronounced “hat”), modifies the type specifier to mean that the declared object should be automatically deleted when the system determines that the object is no longer accessible.”
(aus der Microsoft-Dokumentation zu C++/CX)
Um es einfach auszudrücken, verwendet man in C++/CX den Hat-Operator anstelle des Sternchens (*), um Pointers zu verwalten.
Was die ref-Klasse im Vergleich zur mIDL-Klasse angeht, hier ein Beispiel für eine einfache ref-Klasse:
public ref class Barcode sealed {
public:
Platform::String^ GetType();
Platform::String^ GetText();
private:
Platform::String^ type;
Platform::String^ text;
internal:
Barcode(doo::BarCode::BarCodeItem);
;Sie fungiert als Header-Klasse und die Implementierung befindet sich in einer separaten Datei.
Hier ist ein Beispiel für dieselbe Klasse als mIDL-Schnittstelle:
[bindable]
[default_interface]
runtimeclass Barcode
{
Barcode();
String Text;
String Type;
}Kein großer Unterschied, oder? Nun, das dachten wir auch. Aber die Umstellung auf mIDL ist etwas mühsamer, denn:
- Für mIDL-Dateien bietet Visual Studio keinen Linter (d. h. keine Autovervollständigung) und keine Syntaxhervorhebung an
- Es verfügt über seine eigenen Typen, z. B. wird
Stringin mIDL zuhstringin C++, das noch einmal instd::stringkonvertiert werden muss, um mit dem Kern zu kommunizieren. - Es handelt sich um eine separate Datei, was das Ganze gehörig aufbläht.
1D- und 2D-Barcodes in wenigen Millisekunden auslesen
Senken Sie Kosten und profitieren Sie von Produktivitätszuwächsen, indem Sie zeitraubende Arbeitsabläufe automatisieren.
Barcodes eignen sich hervorragend dafür, da Sie von jedem Mobilgerät mit einer Kamera und der richtigen Software gescannt werden können.
Unser Barcode Scanner SDK lässt sich in wenigen Stunden in Ihre Mobil- oder Web-App integrieren und macht aus Ihren Geräten leistungsfähige Barcode-Scanner.
Laden Sie unsere Demo-App herunter:
Umgang mit nativen Abhängigkeiten
Scanbot SDK hat mehrere systemeigene Abhängigkeiten, darunter openjpeg, zxing, boost, tiff, zlib und OpenCV, das selbst viele systemeigene Binärdateien enthält. Insgesamt sind das etwa 35 Bibliotheken (ohne die nativen Bibliotheken des Scanbot SDK), die manuell hinzugefügt werden müssen, nur um die WinRT-Komponente zu kompilieren.
Mit CMake wäre das eine relativ einfache Aufgabe, aber aufgrund von Zeitvorgaben während der Entwicklung und Einschränkungen der Plattform war es einfacher, dem Muster von Microsoft bei der Erstellung einer WinRT-Komponente zu folgen.
Das bedeutet, dass 35 verschiedene zusätzliche Include-Verzeichnisse unter C/C++ -> General, ungefähr 25 verschiedene zusätzliche Bibliotheksverzeichnisse unter Linker -> General und alle 35 Bibliotheken unter Additional Dependencies unter Linker -> Input hinzugefügt werden.
Diesen Vorgang wiederholt man sowohl für das Release- als auch für das Debug-Ziel und für die x86- wie auch die x64-Architektur. Dabei handelt es sich um den Teil, dessen ordentliche Implementierung am lästigsten ist.
Später stellte ich fest, dass man zusätzliche Verzeichnisse als Variablen direkt in der .vcxproj-Datei definieren kann:
<PropertyGroup>
<CoreDir>$(ProjectDir)\..\..\..\</CoreDir>
<x64ReleaseDir>x64-build-release\</x64ReleaseDir>
<x64DebugDir>x64-build-debug\</x64DebugDir>
<x86DebugDir>x86-build-debug\x86-Clang-Debug\</x86DebugDir>
</PropertyGroup>Das macht die Handhabung von Abhängigkeiten wesentlich übersichtlicher.
Generell würde ich empfehlen, Abhängigkeiten direkt in .vcxproj zu verwalten, auch wenn es mühsam ist. Aber es ist immer noch, und ich wiederhole mich hier, sehr viel besser als die Verwaltung des Ganzen über die Benutzeroberfläche von Visual Studio, die sich seit den 90er Jahren nicht geändert zu haben scheint.
Die Abhängigkeiten werden in der Projektdatei selbst wie folgt definiert:
<ItemDefinitionGroup Condition="'$(Configuration)'=='Debug'">
<ClCompile>
<AdditionalIncludeDirectories Condition="'$(Configuration)|$(Platform)'=='Debug|x64'">
</AdditionalIncludeDirectories>
<AdditionalIncludeDirectories Condition="'$(Configuration)|$(Platform)'=='Debug|x86'">
</AdditionalIncludeDirectories
...
<ClCompile>
<Link>
<AdditionalLibraryDirectories Condition="'$(Configuration)|$(Platform)'=='Debug|x64'">
</AdditionalLibraryDirectories>
<AdditionalDependencies Condition="'$(Configuration)|$(Platform)'=='Debug|x86'">
</AdditionalDependencies>
...
</Link>
</ItemDefinitionGroup>Header fügt man unter dem Compile-Flag hinzu. Sobald die Header hinzugefügt sind, sollte das Projekt kompilieren. Wenn einige Bibliotheksverzeichnisse fehlen, wird der Linker wahrscheinlich einen Fehler wie diesen ausgeben:
Error LNK2019 unresolved external symbol
__itt_thread_set_nameA_ptr__3_0 referenced in function "public:
__cdecl cv::'anonymous namespace'::ThreadID::ThreadID(void)"
(??0ThreadID@?A0xe57175de@cv@@QEAA@XZ)
opencv_core453.lib(system.cpp.obj) 1Etwas kryptisch, oder? Keine Ahnung, was zu tun ist? Sehen wir uns das einmal genauer an.
Wir erkennen, dass opencv_core453 der Teil ist, der sich beschwert. Die Kernbibliothek von OpenCV kann nicht kompiliert werden, weil cdecl externe Symbole nicht finden kann.
Welches ist das fehlende Symbol? __itt_thread_set_nameA_ptr__3_0 ist nicht besonders aussagekräftig.
Schauen wir uns alle Abhängigkeiten an, die im Build-Verzeichnis oder irgendwo sonst existieren. Wir stellen fest, dass das nicht aufgelöste Symbol mit __itt beginnt. Das muss doch etwas bedeuten, oder? Nach einigem Kopfzerbrechen stellte sich heraus, dass ittnotify.lib eine weitere Abhängigkeit ist, die wir hinzufügen müssen, damit das Programm kompiliert werden kann.
Dies war ein relativ rudimentäres Beispiel. Stellen Sie sich jedoch vor, Sie müssten diese Art von Debugging/Recherche für jede womöglich fehlende Abhängigkeit Hunderte von Malen durchlaufen.
Trotzdem ist das mehr oder weniger die Herangehensweise, um nicht verwaltete Abhängigkeiten zu verwalten.
Mit der Zeit wird es besser, da man lernt, zwischen den Zeilen zu lesen, und genau weiß, nach welchen Symbolen man suchen muss. Außerdem lernt man all die nativen Binärdateien kennen. Glücklicherweise bewegen wir uns jetzt auf einer ziemlich niedrigen Ebene, so dass es nicht so viele Bibliotheken gibt, die man kennen muss.
Integration mit der Kernkomponente
So konnten wir schlussendlich das bauen, was ich als grundlegende Architektur bezeichnen würde. Ganz schön zeitraubend, oder? Zunächst mussten wir einen ersten funktionierenden Prototyp erstellen, dann eine native Abhängigkeitsverwaltung verstehen und das Ganze dann von C++/CX auf WinRT/C++ umschreiben.
An diesem Punkt beschlossen wir, die WinRT-Komponente näher an unseren Kerncode heranzuführen.
Wie ich bereits angedeutet habe, ist der Kern des Scanbot SDK ein eigenes Repository. Wir schreiben nicht alles für jede Plattform neu. Die wichtigen Aufgaben (maschinelles Lernen und Bilderkennung) werden auf C++-Ebene in einem eigenen Repository und Ökosystem erledigt.
Es hat zahlreiche Vorteile, den WinRT-Kern des Windows-SDK mit dem Core-SDK selbst zusammenzuhalten und nicht mit der C#-Windows-UI-Schicht. Auf diese Weise kann er in der CI/CD-Pipeline des Kerns ausgeführt werden, was bedeutet, dass wir alle automatischen Tests mit ihm durchführen und sicherstellen können, dass er immer den neuesten Build-Core verwendet usw.
Wie stellen wir das an?
Mein erster Gedanke war, dass wir einfach das Projektverzeichnis selbst verschieben könnten und fertig.
Leider ist das nicht so einfach, denn ein Projekt ist weder eine eigenständig baubare Lösung, noch kann es Paketabhängigkeiten enthalten, die von der Plattform benötigt werden.
Auch kann ein separates Projekt nicht an eine bestehende Lösung angehängt werden... Nun ja, möglich wäre es, würde aber die gesamte Pfadführung durcheinanderbringen.
Wenn wir das Projekt selbst in den Kern verschieben würden, könnten wir es zwar theoretisch bauen, aber die Abhängigkeiten nicht wiederherstellen, da sie Teil derselben Lösung sind. Und zu diesem Zeitpunkt ist die Lösung immer noch das Windows-SDK-Projekt in einem separaten Repository.
Die Lösung bestand darin, eine neue .NET-Lösung (haha) für unsere WinRT-Komponente zu erstellen. Diese enthält alle notwendigen Paketabhängigkeiten und Projektreferenzen.
Die gesamte Projektstruktur sieht zu diesem Zeitpunkt wie folgt aus:
- UWP-Lösung (Windows-Repository)
- Windows SDK Debug-Anwendung (C#)
- Windows SDK (C#)
- WinRT-Lösung (Kern-Repository)
- WinRT-Projekt (C++)
Fehlersuche bei der Bilddekodierung
Nachdem wir etwa anderthalb Monate an der Lösung gearbeitet hatten, war ich mit dem Ergebnis ziemlich zufrieden. Doch als wir die Alpha-Version veröffentlichten, stellte die Qualitätssicherung fest, dass Aztec-Barcodes nicht erkannt wurden.
Im Kernprogramm selbst funktionierte alles einwandfrei, aber beim Testen unter Windows lieferte die Aztec-Erkennung ungültige Ergebnisse für genau die gleichen Bilder. Wir hatten Tests für etwa 20 verschiedene Barcode-Typen und 200 unterschiedliche Barcodes durchgeführt. Nur Aztec machte Probleme.
Das machte uns zunächst stutzig. Würde das Problem bei der Bildverarbeitung in der C#- oder WinRT-Schicht liegen, sollte keine Erkennung stattfinden. Das wäre ein grundlegendes Problem, das jeden Barcode-Typ beträfe.
Aber nein, es war nur Aztec.
Ich habe einige Tage damit verbracht, den Kern selbst sowohl unter Windows als auch auf einem MacBook zu debuggen. Jede Zahl im Prozess selbst war identisch, von der Bildauflösung vor und nach TensorFlow bis hin zur Anzahl der gefundenen Fehler und Punkte.
Hier fing ich wieder an, mir die Haare zu raufen. Ich holte tief Luft und ging joggen. Dabei wurde mir klar, dass das Problem irgendwo in dem von mir geschriebenen Code liegen musste, da Aztec-Barcodes von der durch den Code erstellten CLI-Engine erkannt werden konnten.
Nach einigem Herumprobieren fiel mir auf, dass die automatisierten Tests die folgende Zeile enthielten:
cv::normalize(inputImage, debugImage, 0, 255, cv::NORM_MINMAX, CV_8U);Die Bilder wurden in CV_8U normalisiert, aber ich hatte CV_8UC4 dtype verwendet, um die Pixel in das OpenCV-Format zu übersetzen. Nun, vielleicht waren die Kanäle daran schuld.
Das ergab aber immer noch nicht viel Sinn. Wenn das ein echtes Problem wäre, würden wir das auch bei anderen Barcode-Typen sehen.
Aber warum nicht, lassen wir es darauf ankommen. Wenn es sich um ein 4-Kanal-Bild handelt, sollten wir es so transformieren, dass es keinen Alphakanal hat. Also habe ich die folgende Transformation zur Matrix hinzugefügt:
cv::cvtColor(mat, mat, cv::COLOR_BGRA2BGR);Nachdem ich den Alphakanal entfernt hatte, funktionierte Aztec. Es funktionierte einfach. Das alles ergab für mich nicht viel Sinn.
Nun, am Ende stellten wir fest, dass das Problem in der Mathematik der Dekodierung des Aztec-Formats steckte. Sie interpretierte den Alphakanal als einen weiteren Farbkanal, was die 8-Bit-Matrixverschiebung verursachte.
Ich hatte eigentlich erwartet, dass diese Saga ein grandioseres oder mysteriöseres Ende nehmen würde. Die Fehlersuche führte mich an einige dunkle Orte, und ich wünschte, ich hätte beispielsweise ein Problem im TensorFlow-Repository eröffnen können.
Aber so ist das bei der Softwareentwicklung meistens. Man fühlt sich wie ein Ermittler, der eine große Verschwörung aufdeckt, aber am Ende stellt sich heraus, dass es nur ein Tippfehler war.
Herumspielen mit Kamerakonfigurationen
Einer der faszinierendsten Aspekte dieses Projekts war es, mehr über Kameratechnologien zu erfahren. Windows bietet keine praktische API, mit der alles sofort funktioniert, wie es bei iOS und Android der Fall ist.
Das bedeutet, dass man sich wirklich die Hände schmutzig machen muss, um das bestmögliche Bild aus der Kamera herauszuholen.
Man muss sich mit den Fokusmodi auskennen. Was ist kontinuierlicher Fokus, was ist Autofokus? In welchen Situationen ist der manuelle Fokus erforderlich? Hinzu kommt, dass einige Laptops Objektive mit fester Fokussierung haben, bei denen der Modus nicht angepasst werden kann. Diese Szenarien muss man berücksichtigen.
Ich bin bei weitem kein Experte auf dem Gebiet der Fotografie, aber ich würde sagen, dass man die folgenden Dinge berücksichtigen sollte, wenn man mit einer Kamera-API herumspielt:
Belichtung, Belichtungskorrektur, Blitz, Fokushilfslicht, ISO-Geschwindigkeit, optische Bildstabilisierung, Netzfrequenz und Weißabgleich.
Vor diesem Projekt hatte ich von vielen dieser Begriffe noch nie etwas gehört. Aber um ehrlich zu sein, war dies einer der interessanteren Teile des Projekts. Ich empfehle jedem, der sich zumindest ein bisschen für Kameratechnik interessiert, mit diesen Konfigurationen zu experimentieren.
Distribution
Die Distribution der internen Entwickler-App war ein kleiner Albtraum, da Windows weder die Freiheit von Android bietet, wo man einfach die APK installieren kann, noch die Infrastruktur von iOS, wo man Geräte registrieren und die ipa intern mit über das Unternehmensprogramm verteilen kann.
Man benötigt ein vertrauenswürdiges Zertifikat in den Stammzertifikaten, aber Microsoft bietet keine bequeme Möglichkeit, dies zu erreichen, ohne die App in den Store hochzuladen.
Es muss also manuell erfolgen, was ein bisschen mühsam ist. Irgendwann werde ich versuchen, ein Skript zu schreiben, um den Prozess zumindest ein wenig zu vereinfachen. Eine andere Möglichkeit wäre die Nutzung des internen Beta-Kanals des Microsoft Store, aber die Verwaltung der internen Tests über diesen Kanal ist etwas umständlich.
Leider ist die einzige Möglichkeit für die QA, die Software zu testen, die Installation von Visual Studio auf ihren eigenen Windows-Geräten.
Fazit
Was für eine Achterbahnfahrt. In mancher Hinsicht war es ein chaotisches Durcheinander, und das spiegelt sich auch in diesem Beitrag wider. Aber es war auch sehr interessant, alles mögliche über das Innenleben des Microsoft-Ökosystems zu erfahren. Diese Erfahrung war für mich ungemein wertvoll.
Wenn das Team wächst, wird die Logik zur Einbindung nativer Abhängigkeiten höchste Priorität bei der Überarbeitung haben. Microsofts bevorzugter Ansatz für das Hinzufügen nativer Abhängigkeiten zu WinRT-Komponenten hat sich als sehr umständlich erwiesen. Wir brauchen ein ordentliches CMake-Build, um Abhängigkeiten zu handhaben.
Wir müssen zudem einen einfacheren Weg finden, um unser Produkt intern zu verteilen. Die manuelle Installation von Zertifikaten ist nichts, was wir im Jahr 2023 noch tun sollten. Wenn jemand eine Idee hat, bitte melden!