Searchable PDF
Extract data from a scanned document with OCR
Enterprises that use our solutions





Efficient document processing using machine learning
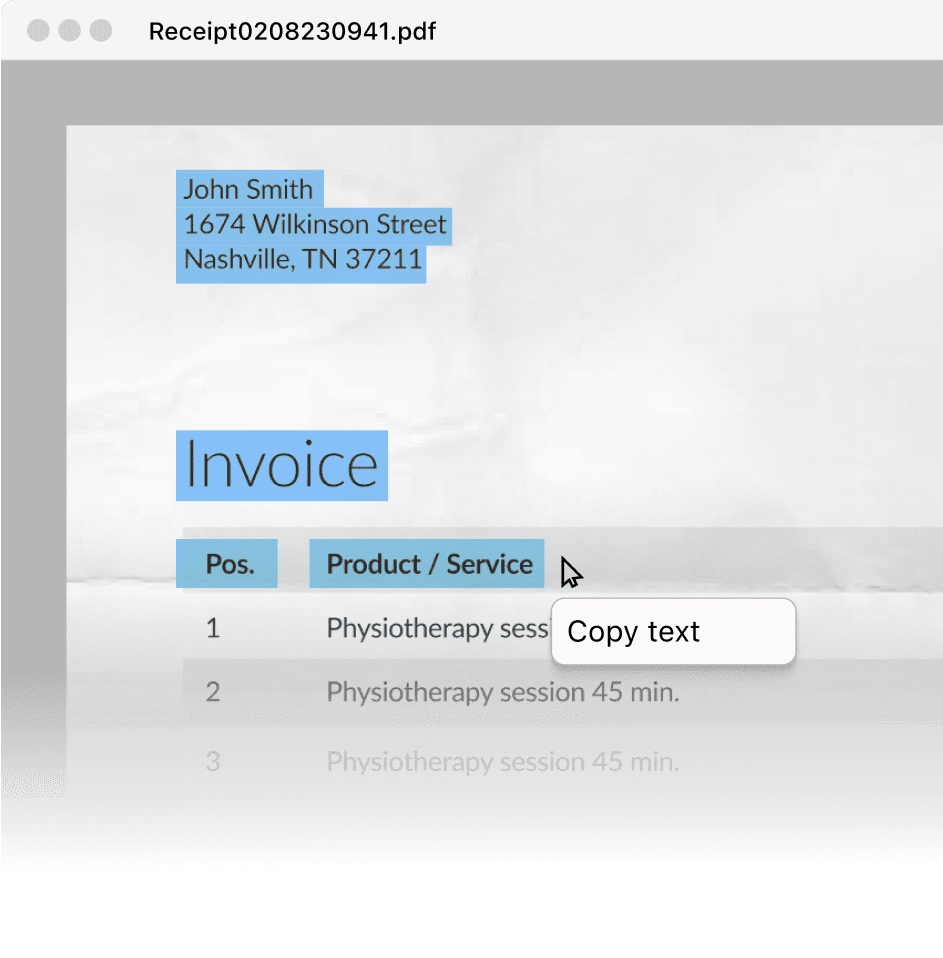
Using optical character recognition (OCR), a scanned document image can be turned into a searchable PDF. This enables efficient document management: Instead of looking for a specific file among hundreds of documents in your system, you can do a full-text search for the content to find it instantly.
The visible appearance of the document is preserved, as the original document image is simply overlaid with an invisible text layer. This layer makes the file searchable and also enables highlighting, copying, and pasting. Transferring information from searchable PDFs prevents the errors typically resulting from manual data entry.
The digitization of analog text with OCR software enables process automation and easier access to information. Employees looking for a specific document can enter related search terms to find exactly what they need in seconds, saving time and money.
Turn paper documents into PDFs
Copy and paste data to minimize human errors
Enable backend systems to process data automatically
Would you like to know more about our pricing?
Get in touch with us and receive more pricing details within a day.
Learn more about our scanning solutions
See all resourcesDocument Scanning
Whitepaper
Use cases, benefits & everything else you need to know about mobile Document Scanning
Learn More
Document Scanning
Brochure
Learn everything you need to know about Document Scanning with Scanbot SDK
Learn More
Document Scanner
Infographic
7 features you shouldn’t miss out on
Learn More
Developers, ready to get started?
Adding our free trial to your app is easy. Download the Scanbot SDK now and discover the power of mobile data capture